By Becca Wolf | Bond LSC
When one hears of a magician, they think of a man that pulls a rabbit out of a top hat or ‘cuts’ people in half. Magicians have a lot of tricks up their sleeve.
People do not think of scientists as magicians, yet they still perform wonderous things.
“I heard a quote one time that says science and technology is kind of like magic,” Jordan Brungardt said. “For somebody that doesn’t know what is happening, experiments look like magic if they’re performed well. Think of cell phones allowing us to talk to people across the world. For somebody from a few decades ago, that would seem like magic.”
For Brungardt, a post-doctoral fellow in the Gary Stacey lab at Bond Life Sciences Center, this magic of sorts makes research exciting.
“When you get sequencing information back in the lab after going weeks without actually seeing something and it lines up with what you’re predicting, it’s like Christmas,” Brungardt said.
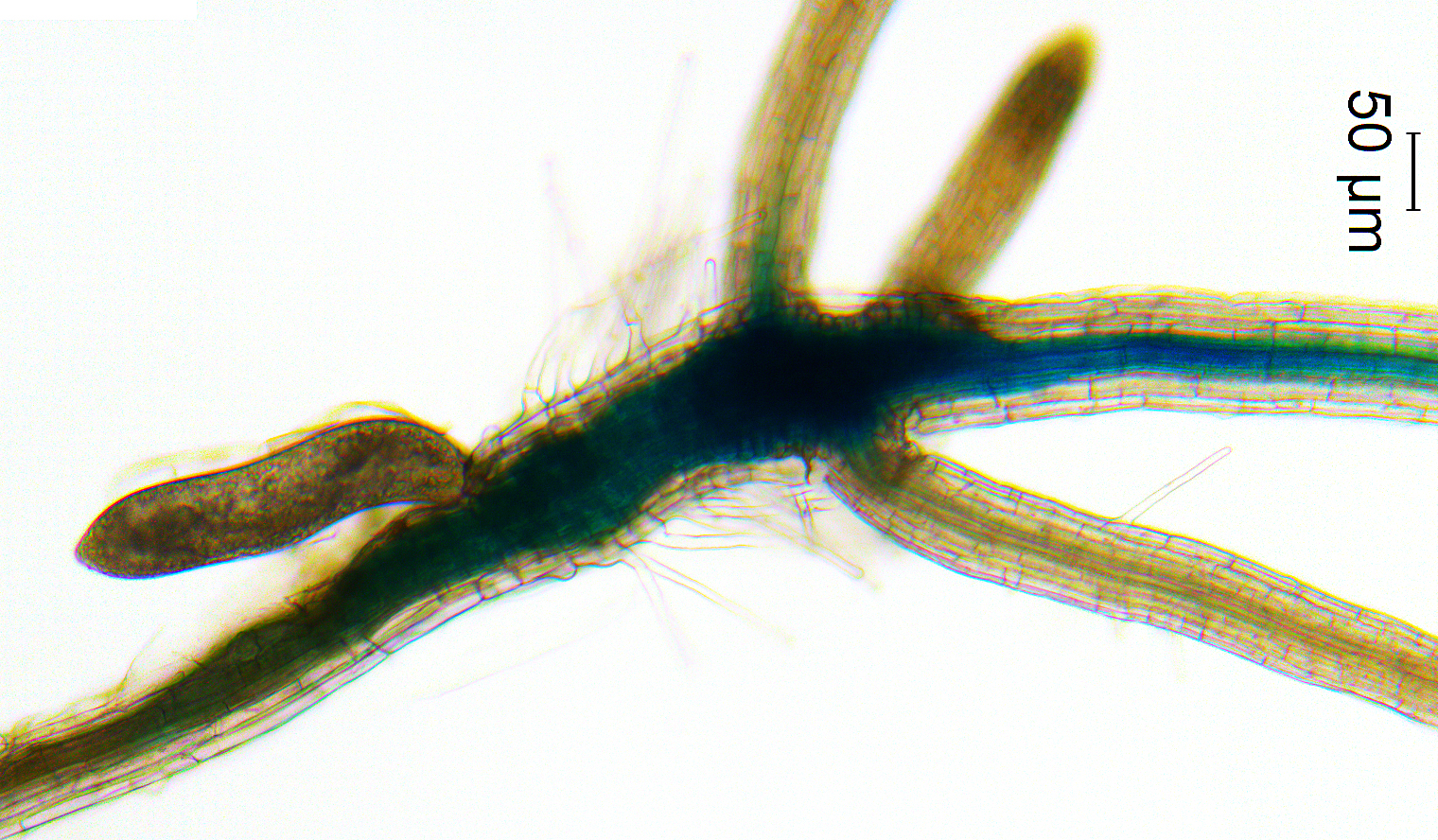
In the Stacey lab, Brungardt studies the genes involved in early nodule development in soybeans.
He looks at the interaction between rhizobia, a species of bacteria, and their plant hosts, legumes. His work aims to explore how the plants allow access to their inner roots through infection thread development.
“They undergo an intimate interaction that is really unique,” Brungardt said. “It’s pretty cool from that aspect, and the infection thread is an important part of the interaction.”
Brungardt currently works with Jaehyo Song, a postdoctoral student in the Stacey lab.
“He is a very careful person, and experimenting together helps prevent any mistakes,” Song said. “I can also see that the experiment is progressing step by step because we work very diligently.”
The two have been working together for a few months and have found their collaboration to be very beneficial.
“Even when a simple problem occurred in the experiment, he did not ignore it,” Song said. “He found the exact cause of the problem through previous research and eventually solved it. Through this, I could see that his problem-solving skills were very good.”
Brungardt is able to dodge problems that arise in his research easily.
“There’s a lot of different facets of my research,” Brungardt said. “If I get stuck somewhere, I can make headway somewhere else, which allows me to take my time on the process that I’m stuck on and come back to it later.”
Brungardt completed his undergraduate degree at Fort Hays State University in Kansas and his master’s degree at Wichita State University. That wasn’t his initial plan, though.
“I knew I wanted to do something with soybeans coming out of my undergrad and, to be honest, I actually interviewed with Dr. Stacy, who is my mentor right now, but it didn’t work out,” Brungardt said. “So, it was really nice coming back and getting a job here, because that’s what I initially wanted to do.”
Even though Brungardt did not initially come to Mizzou, he remained focused on it as the end goal. He ended up getting a job as a microbiologist where he produced Rhizobia for farmers to use to improve their crop production.
“My Ph.D. dealt with microbial interaction with plants, so it still had some loose application for what I’m doing now,” Brungardt said. “While my path wasn’t straight, it never strayed from what I wanted to do. I liked that I still did things that were relevant to what I wanted to do.
Brungardt arrived at Bond LSC last June and has adjusted nicely. His research is similar to what he has done previously, just in a new building in a new lab. He is happy to finally be able to completely focus on his research.
“I just graduated with my Ph.D. last year so there’s no more homework or classes for me. It’s a little bit of a change,” Brungardt said. “It’s simpler, I don’t have to break up my workday to go to class and then come back and work, and then switch up to something again. As a student I was doing several things at once and had other things in the back of my mind. Now I can just focus on my research.”
Since Brungardt can devote all of his time to his research now, he expects to see a lot more magical moments in the lab.